Opisany przykład dotyczy projektu integracji z zewnętrznym systemem, który ma na celu synchronizacje ruchów magazynowych z systemu produkcyjnego do systemu księgowego. Eksport danych wywoływany jest na żądanie użytkownika.
Istotne założenia:
Moment rozchodu materiału do produkcji jest uzależniony od statusu produkcyjnego zlecenia. Moment ten jest osiągany przez różny status w zależności od linii produkcyjnej, na którą trafił wyrób.
Eksport ma być możliwy dla dnia lub zakresu dat, z uwzględnieniem ruchów historycznych.
W systemie produkcyjnym, z którego dane są eksportowane, zlecenia podzielone są na grupy wyrobów i mogą być przypisane do różnych linii produkcyjnych. Każda z grup ma zapisaną informację o obecnym statusie produkcji oraz o jego poprzednikach. I teraz dochodzimy do sedna dzisiejszego wpisu – historia ich wystąpień zapisana jest w jednym ciągu znaków.
Poniżej przykładowa struktura tabeli oraz zlecenie o nr 100, na którym będę bazował.
SELECT * FROM OrderGroups WHERE OrderNr = 100

Zlecenie podzielone jest na wspominane już grupy produkcyjne. Pozycje tego zlecenia są z nimi powiązane, ale relacje między nimi opisane są w innej tabeli i nie mają znaczenia w omawianym przypadku. Musimy móc wskazać zlecenie i grupę, do której wydany został materiał. Moment tego rozchodu uzależniony jest od daty ustalenia statusu produkcji. Jednakże zapisana w bazie forma nie sprzyja ani wygodnemu, ani wydajnemu wyszukiwaniu tych danych.
Rozwiązanie najwygodniejsze, ale dostępne dopiero od wersji SQL Servera 2016. SPLIT_STRING to funkcja tabelaryczna, która przyjmuje dwa parametry:
STRING_SPLIT (ciąg znaków, separator)
Gdy po prostu wstawimy ciąg znaków do funkcji, to składnia i jej wykonanie wygląda tak:
SELECT VALUE AS'StatusBookings' FROM STRING_SPLIT('A=2020-05-20 15:38:30 ;B=2020-05-21 10:12:30;C=2020-05-22 20:30:15',';')
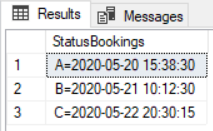
Jeżeli jednak chcemy wartość ciągu przekazać dynamicznie z tabeli, to musimy zastosować CROSS APPLY po zapytaniu.
SELECT OrderNr, OrderGrpNr, value as 'StatusBookings' FROM OrderGroups CROSS APPLY STRING_SPLIT(ProductionStatusHistory,';') WHERE OrderNr = 100
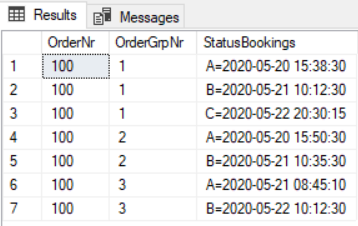
W ten sposób mamy przygotowaną tabelę pod bardziej wygodniejsze i wydajniejsze przeszukiwanie danych. Dla porządku drobna korekta i mamy zaprezentowane informacje w przejrzystej formie.
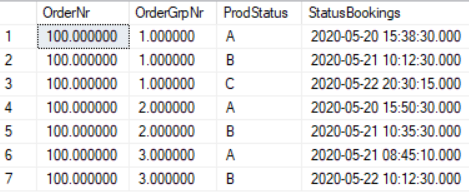
SELECT OrderNr, OrderGrpNr, SUBSTRING(value,1,1) as 'ProducitonStatus', CAST(SUBSTRING(value,3,LEN(value)-2) as datetime) as 'StatusBookings' FROM OrderGroups CROSS APPLY STRING_SPLIT(ProductionStatusHistory,';') WHERE OrderNr = 100
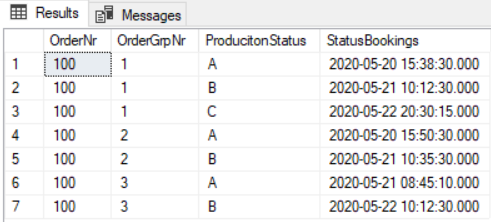
To proste i wygodne rozwiązanie, gdy mamy do czynienia z bardziej aktualnymi wersjami SQL Servera. Gdy nie mamy tej przyjemności to wtedy…
Zabawa staje się trochę bardziej skomplikowana. W T-SQLu istnieje możliwość generowania danych w formacie XML i możemy ten format wykorzystać, by rozdzielić wartości w polu tekstowym do osobnych wierszy.
Kroki w tym działaniu mamy dwa:
- Wygenerowanie XMLa, który będzie miał rozbite informacje o księgowaniach statusu.
- Przedstawienie danych z XMLa z powrotem w formie tabeli.
W tej sytuacji trzeba wykorzystać klauzulę FOR XML PATH (), która odpowiada za generowanie struktury XML z zapytania SQL. Podstawową zasadą wykorzystania jest dopisanie jej po sekcji from z informacją o nazwie węzła głównego. Jeżeli chcemy tworzyć kolejne węzły i ich zagłębienia, to tworzymy w środku podzapytanie, które również korzysta z tej samej klauzuli.
DECLARE @XML XML =
(
SELECT TOP 1
O1.OrderNr as '@OrdeNr',
(
SELECT
OrderGrpNr,
CAST(('<ProdStatus><Value>'
+
REPLACE(O2.ProductionStatusHistory,';' ,'</Value></ProdStatus><ProdStatus><Value>')
+
'</Value></ProdStatus>') as XML) ProductionStatuses
FROM OrderGroups O2
WHERE O2.OrderNr = O1.OrderNr
FOR XML PATH ('OrderGroups'),type
)
FROM OrderGroups O1
WHERE O1.OrderNr = 100
FOR XML PATH ('Order')
)
SELECT @XML
Ważnym elementem zapytania jest sekcja ProductionStatuses, która rozbija ciąg znaków z historią statusów poprzez zastosowanie funkcji REPLACE. Wymieniany jest separator na początki oraz rozpoczęcia poszczególnych elementów węzła. Dodatkowo dopisałem do każdego statusu produkcji numer zlecenia oraz grupy w formie atrybutu. Wszystko to zwieńczone jest funkcją CAST, która konwertuje ten podmieniony ciąg do formatu XML.
Wynikiem tego zapytania jest poniższa struktura:
<OrderGroupLists>
<OrderGroup>
<ProductionStatuses>
<ProdStatus OrderNr="100" GrpNr="1">
<Value>A=2020-05-20 15:38:30 </Value>
</ProdStatus>
<ProdStatus OrderNr="100" GrpNr="1">
<Value>B=2020-05-21 10:12:30</Value>
</ProdStatus>
<ProdStatus OrderNr="100" GrpNr="1">
<Value>C=2020-05-22 20:30:15</Value>
</ProdStatus>
</ProductionStatuses>
</OrderGroup>
<OrderGroup>
<ProductionStatuses>
<ProdStatus OrderNr="100" GrpNr="2">
<Value>A=2020-05-20 15:50:30 </Value>
</ProdStatus>
<ProdStatus OrderNr="100" GrpNr="2">
<Value>B=2020-05-21 10:35:30</Value>
</ProdStatus>
</ProductionStatuses>
</OrderGroup>
<OrderGroup>
<ProductionStatuses>
<ProdStatus OrderNr="100" GrpNr="3">
<Value>A=2020-05-21 08:45:10 </Value>
</ProdStatus>
<ProdStatus OrderNr="100" GrpNr="3">
<Value>B=2020-05-22 10:12:30</Value>
</ProdStatus>
</ProductionStatuses>
</OrderGroup>
</OrderGroupLists>
Teraz musimy wrócić do oczekiwanej formy tabelarycznej. Z pomocą przychodzi nam metoda nodes, którą można wykorzystać dla zdefiniowanego w zmiennej XMLa jako źródła danych. Poniżej zapytanie, które wygląda następująco:
SELECT
XMLGroupProductionStatuses.value('(./@OrderNr)[1]', 'decimal(18,6)') AS 'OrderNr',
XMLGroupProductionStatuses.value('(./@GrpNr)[1]', 'decimal(18,6)') AS 'OrderGrpNr',
XMLGroupProductionStatuses.value('(./Value)[1]', 'nvarchar(100)') AS 'ProdStatus'
FROM
@XML.nodes('/OrderGroupLists/OrderGroup/ProductionStatuses/ProdStatus') as ref(XMLGroupProductionStatuses)
Jako tabelę wskazujemy zadeklarowanego w zmiennej XMLa. Za pomocą metody nodes definiujemy miejsce strukturze pliku, z którego chcemy zebrać dane. W tym przypadku wskazuję węzeł ProductionStatuses, który zawiera elementy ProdStatus – to w nich mamy dostępne informacje o wszystkich księgowaniach statusów.
W sekcji select wybieramy dane z elementów, które nas interesują. Zastosowanie kropki oznacza, że operujemy na węźle, który mamy wybrany w sekcji from. Istnieje możliwość wskazania ścieżki do innego węzła w XMLu, jeżeli potrzebujemy takie dane uzyskać.
Zastosowanie [1] po określeniu lokalizacji oznacza, że chcę wydobyć pierwszy element z danego zbioru (węzła). Forma i działanie jest identyczne jak w wielu językach programowania i operacji na tablicach.
Na końcu podajemy jeszcze w jakim typie danych chcemy zwrócić oczekiwaną wartość. Efektem takiego zapytania jest rezultat zaprezentowany poniżej:
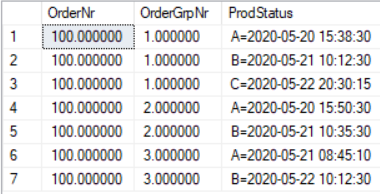
Na koniec zróbmy jeszcze drobną korektę, która da nam rezultat końcowy:
SELECT
XMLGroupProductionStatuses.value('(./@OrderNr)[1]', 'decimal(18,6)') AS 'OrderNr',
XMLGroupProductionStatuses.value('(./@GrpNr)[1]', 'decimal(18,6)') AS 'OrderGrpNr',
SUBSTRING(XMLGroupProductionStatuses.value('(./Value)[1]', 'nvarchar(1000)'),1,1) AS 'ProdStatus',
CAST(SUBSTRING(XMLGroupProductionStatuses.value('(./Value)[1]', 'nvarchar(100)'),3,LEN(XMLGroupProductionStatuses.value('(./Value)[1]', 'nvarchar(1000)'))-2) as datetime) as 'StatusBookings'
FROM
@XML.nodes('/OrderGroupLists/OrderGroup/ProductionStatuses/ProdStatus') as ref(XMLGroupProductionStatuses)
Podobał Ci się ten wpis? Zapraszam do mojej listy mailingowej by otrzymać więcej dodatkowych materiałów oraz być na bieżąco z nowościami!

Q&A – Jak zostać KONSULTANTEM ERP?
-
Dawid Cegła
- 16 października, 2023

Produktywność w pracy
-
- 14 marca, 2021
